Web scraping and web crawling may look similar at first. The reason is that people use them interchangeably. Yet, there are differences between them that are unnoticeable at first but also very important because they define both of these processes.
Many fields of modern data operations require a web scraping and web crawling. These include but are not limited to search engine indexing, machine learning, and big data analytics. Moreover, in order to extract data from websites, you will need to utilize both web scraping and web crawling.
The need to use both web scraping and web crawling at the same time can only add to the confusion between the two. The previous statement is especially true for websites that contain product categories. In order to gather all the URLs from such a page, you would need to set up a crawler. The next step would be to use a web scraper that would fetch product details from the aforementioned URLs.
But in order to completely differentiate between web crawling and web scraping, you must first understand what these processes are. In other words, by defining them and understanding their core principles, the differences become clear and visible.
What Are Web Crawling and Web Scraping?
Web Scraping
With web scraping, you gather specific data from the web and copy it to a spreadsheet or a central local database. Later, you can further manipulate it through data retrieval and use it for data analysis. Web scraping is often used for data mining, web mining, price comparison, web data integration, contact scraping, etc.
In order to web scrape a webpage, you will need to utilize processes called fetching and extraction. Fetching is the downloading of a certain webpage. Once the page is fetched, the extraction process begins. That’s when web scrapers usually take something out from a fetched page in order to use that somewhere else. It might even have a different purpose altogether.
Web Crawling
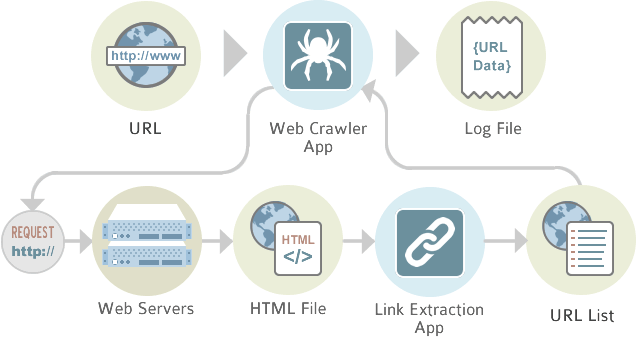
On the other hand, web crawling is a process which requires web crawlers, otherwise called spiders. These crawlers are internet bots that systematically browse the World Wide Web. That’s why web crawling is pretty common with search engines. Thanks to it, the search engines can update their web content, and users can search more efficiently.
Such crawlers often visit websites without approval. As a result, some websites may include a robots.txt file which can request web crawlers to index nothing or only a percentage of the website.
What Are the Major Differences Between the Two?
The major difference between web scraping and web crawling is that the former extract information from the web for further use, while the latter only indexes information via spiders.
The next difference is related to the scale of these processes. You can utilize web scraping at any scale because it is a specific data extraction that can happen anywhere on the web. In contrast, web crawling will map all dedicated resources for further extraction and possibly scraping. And because the mapping includes all relevant information, you can say that web crawling is mostly done on a large scale.
Finally, you can differentiate between these processes by how demanding they are. You can configure data scraping quite easily because scraping tools are usually straightforward nowadays, and you will be able to configure them to do a specific task on any scale. For example, this task can include ignoring or overcoming all possible obstacles.
On the other hand, efficient web crawling is only possible by hiring a team of professionals. The reason is that only professionals can configure spiders in order to comply with all the demands from the servers.
How to Use a Proxy for Scraping Efficiently
Proxy servers work as an intermediary between you and a certain website. If you make an HTTP request while using a proxy, this request will first pass through it and then reach the website in question. Thanks to that, the website won’t recognize that you were the one who has sent the request.
It’s advisable that you use proxies for scraping, like those found here. It can help you get past the rate limits on the targeted website and hide your IP address.
For example, there might be a large number of requests coming from your IP address in a short period of time. Some websites may render these requests suspicious. If this happens, you will get an error message. As a result, all your future requests will be blocked for a certain period of time.
In order to avoid these restrictions, you can spread a considerable amount of requests over multiple proxy servers. The reason is that each proxy server has its own IP address. The website in question will only see a handful of requests from each of these IPs. So, you can scrape efficiently through numerous requests at once because they will stay under the rate limits.